Setup
First, we will load the AEME and aemetools
package:
Create a folder for running the example calibration setup.
# tmpdir <- "calib-test"
# dir.create(tmpdir, showWarnings = FALSE)
tmpdir <- tempdir()
aeme_dir <- system.file("extdata/lake/", package = "AEME")
# Copy files from package into tempdir
file.copy(aeme_dir, tmpdir, recursive = TRUE)
#> [1] TRUE
path <- file.path(tmpdir, "lake")
list.files(path, recursive = TRUE)
#> [1] "aeme.yaml" "data/hypsograph.csv" "data/inflow_FWMT.csv"
#> [4] "data/lake_obs.csv" "data/meteo.csv" "data/outflow.csv"
#> [7] "data/water_level.csv" "model_controls.csv"Build AEME ensemble
Using the AEME functions, we will build the AEME model
setup. For this example, we will use the glm_aed model. The
build_aeme function will
aeme <- yaml_to_aeme(path = path, "aeme.yaml")
model_controls <- AEME::get_model_controls()
inf_factor = c("dy_cd" = 1, "glm_aed" = 1, "gotm_wet" = 1)
outf_factor = c("dy_cd" = 1, "glm_aed" = 1, "gotm_wet" = 1)
model <- c("glm_aed")
aeme <- build_aeme(path = path, aeme = aeme, model = model,
model_controls = model_controls, inf_factor = inf_factor,
ext_elev = 5, use_bgc = FALSE)Run the model ensemble using the run_aeme function to
make sure the current model setup is working.
aeme <- run_aeme(aeme = aeme, model = model, verbose = FALSE,
path = path)
#> Running models... (Have you tried parallelizing?) [2025-07-17 13:00:57]
#> GLM-AED running... [2025-07-17 13:00:57]
#> GLM-AED run successful! [2025-07-17 13:00:58]
#> Model run complete![2025-07-17 13:00:58]
#> Retrieving and formatting temp for model glm_aed
#> Retrieving and formatting salt for model glm_aed
plot(aeme)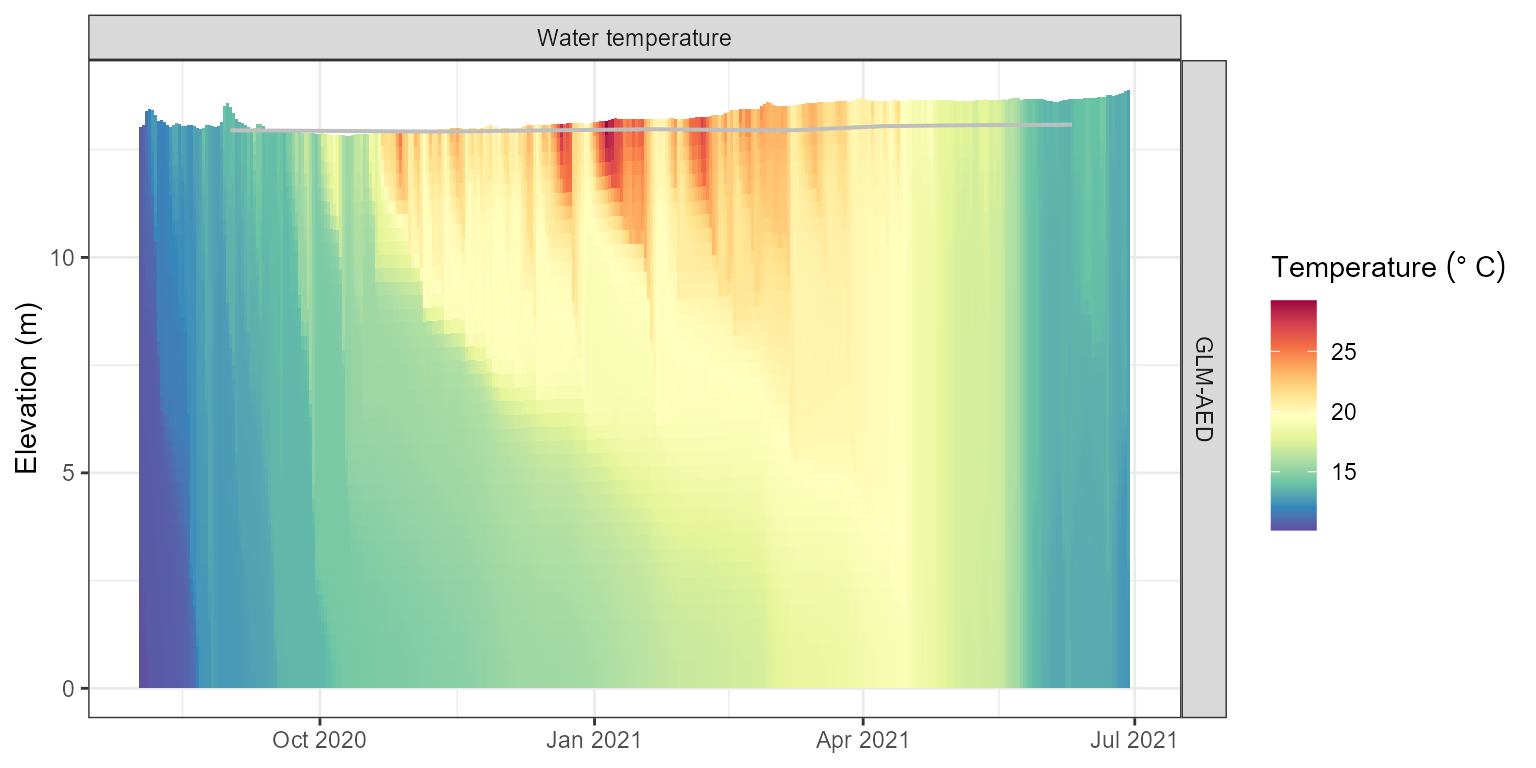
Water temperature contour plotfor the model output.
Load parameters to be used for the calibration
Parameters are loaded from the aemetools package within
the aeme_parameters dataframe. The parameters are stored in
a data frame with the following columns:
model: The model namefile: The file name of the model parameter file. For meteorological scaling variables, “met” is used, whereas for scaling factors for inflow and outflow, “inflow” an “outflow” is used accordingly.name: The parameter namevalue: The parameter valuemin: The minimum value of the parametermax: The maximum value of the parametermodule: The module of the parametergroup: The group of the parameter. Only used for phytoplankton and zooplankton parameters.
Parameters to be used for the calibration.
utils::data("aeme_parameters", package = "AEME")
aeme_parameters|>
DT::datatable(options = list(pageLength = 4, scrollX = TRUE))This dataframe can be modified to change the parameter values. For
example, we can change the light/Kw parameter for the
glm_aed model to 0.1:
aeme_parameters[aeme_parameters$model == "glm_aed" &
aeme_parameters$name == "light/Kw", "value"] <- 0.1
aeme_parameters| model | file | name | value | min | max | module | group |
|---|---|---|---|---|---|---|---|
| glm_aed | glm3.nml | light/Kw | 1.0e-01 | 0.100 | 5.52e+00 | hydrodynamic | NA |
| glm_aed | met | MET_wndspd | 1.0e+00 | 0.700 | 1.30e+00 | hydrodynamic | NA |
| glm_aed | met | MET_radswd | 1.0e+00 | 0.700 | 1.30e+00 | hydrodynamic | NA |
| glm_aed | glm3.nml | mixing/coef_mix_conv | 1.4e-01 | 0.100 | 2.00e-01 | hydrodynamic | NA |
| glm_aed | glm3.nml | mixing/coef_wind_stir | 2.1e-01 | 0.200 | 3.00e-01 | hydrodynamic | NA |
| glm_aed | glm3.nml | mixing/coef_mix_shear | 1.4e-01 | 0.100 | 2.00e-01 | hydrodynamic | NA |
| glm_aed | glm3.nml | mixing/coef_mix_turb | 5.6e-01 | 0.200 | 7.00e-01 | hydrodynamic | NA |
| glm_aed | glm3.nml | mixing/coef_mix_hyp | 7.4e-01 | 0.400 | 8.00e-01 | hydrodynamic | NA |
| glm_aed | wdr | outflow | 1.0e+00 | 0.500 | 2.50e+00 | hydrodynamic | NA |
| glm_aed | inf | inflow | 1.0e+00 | 0.500 | 2.50e+00 | hydrodynamic | NA |
| gotm_wet | gotm.yaml | turbulence/turb_param/k_min | 6.0e-07 | 0.000 | 1.00e-05 | hydrodynamic | NA |
| gotm_wet | gotm.yaml | light_extinction/A/constant_value | 5.5e-01 | 0.395 | 6.59e-01 | hydrodynamic | NA |
| gotm_wet | gotm.yaml | light_extinction/g1/constant_value | 5.9e-01 | 0.440 | 7.40e-01 | hydrodynamic | NA |
| gotm_wet | gotm.yaml | light_extinction/g2/constant_value | 2.0e-01 | 0.050 | 2.70e+00 | hydrodynamic | NA |
| gotm_wet | met | MET_wndspd | 1.0e+00 | 0.700 | 1.30e+00 | hydrodynamic | NA |
| gotm_wet | met | MET_radswd | 1.0e+00 | 0.700 | 1.30e+00 | hydrodynamic | NA |
| gotm_wet | wdr | outflow | 1.0e+00 | 0.500 | 2.50e+00 | hydrodynamic | NA |
| gotm_wet | inf | inflow | 1.0e+00 | 0.500 | 2.50e+00 | hydrodynamic | NA |
| dy_cd | cfg | light_extinction_coefficient/7 | 9.0e-01 | 0.100 | 1.40e+00 | hydrodynamic | NA |
| dy_cd | dyresm3p1.par | vertical_mixing_coeff/15 | 2.0e+02 | 50.000 | 7.50e+02 | hydrodynamic | NA |
| dy_cd | met | MET_wndspd | 1.0e+00 | 0.700 | 1.30e+00 | hydrodynamic | NA |
| dy_cd | met | MET_radswd | 1.0e+00 | 0.700 | 1.30e+00 | hydrodynamic | NA |
| dy_cd | wdr | outflow | 1.0e+00 | 0.500 | 2.50e+00 | hydrodynamic | NA |
| dy_cd | inf | inflow | 1.0e+00 | 0.500 | 2.50e+00 | hydrodynamic | NA |
This dataframe can be passed to the run_aeme_param
function to run AEME with the parameter values specified in the
dataframe. This function is different to the run_aeme
function in that it does not return an aeme object, but the
model output is generated within the lake folder.
run_aeme_param(aeme = aeme, param = aeme_parameters,
model = model, path = path)
#> Running models... (Have you tried parallelizing?) [2025-07-17 13:01:03]
#> GLM-AED running... [2025-07-17 13:01:03]
#> GLM-AED run successful! [2025-07-17 13:01:04]
#> Model run complete![2025-07-17 13:01:04]Calibration setup
Choosing variables to calibrate
Choosing which variables to calibrate is an important step in the calibration process. The variables to calibrate are usually selected based on the availability of data and the importance of the variable to the model.
There is a function within the AEME package called
get_mod_obs_vars which can be used to get the available
variables for which there is modelled and observed data.
available_vars <- AEME::get_mod_obs_vars(aeme = aeme, model = model)
available_vars
#> Salinity Water temperature
#> "CHM_salt" "HYD_temp"
#> Thermocline depth Centre of buoyancy
#> "HYD_thmcln" "HYD_ctrbuy"
#> Epilimnion depth Hypolimnion depth
#> "HYD_epidep" "HYD_hypdep"
#> Schmidt stability Metalimnetic oxygen minima
#> "HYD_schstb" "CHM_oxymom"
#> Number of anoxic layers Water level
#> "CHM_oxynal" "LKE_lvlwtr"There are 10 variables available for calibration, this includes derived variables such as thermocline depth (HYD_thmcln) and Schmidt stability (HYD_schstb).
For this example, we will calibrate the water temperature and lake
level. The variables are selected using the AEME variable definition
e.g. c("HYD_temp", "LKE_lvlwtr").
vars_sim <- c("HYD_temp", "LKE_lvlwtr")Define fitness function
First, we will define a function for the calibration function to use
to calculate the fitness of the model. This function takes a dataframe
as an argument. The dataframe contains the observed data
(obs) and the modelled data (model). The
function should return a single value.
Here we use the root mean square error (RMSE) as the fitness function:
Different functions can be applied to different variables. For example, we can use the RMSE for the lake level and the mean absolute error (MAE) for the water temperature:
Then these would be combined into a named list of functions which
will be passed to the calib_aeme function. They are named
according to the target variable.
# Create list of functions
FUN_list <- list(HYD_temp = mae, LKE_lvlwtr = rmse)Define control parameters
Next, we will define the control parameters for the calibration. The
control parameters are generated using the create_control
funtion and are then passed to the calib_aeme function. The
control parameters for calibration are as follows:
?create_control| create_control | R Documentation |
Create control list for calibration or sensitivity analysis
Arguments
method |
The method to be used. It can be either "calib" for calibration or "sa" for sensitivity analysis. |
... |
Additional arguments to be passed to the function
For calibration, the arguments are:
For sensitivity analysis, the arguments are:
|
Here is an example of the control parameters for calibration, with a
value-to-reach of 0, 40 members in each population, maximum number of
iterations of 400, a relative tolerance of 0.07, 25% of parameters in
each population need to be non-NA to be used as parents in the next
generation, 10% of the children parameters undergo random mutation,
parallel processing is used, the file type for writing the results is
CSV, the NA value is 999 and 2 cores are used for parallel processing.
The control parameters are stored in the ctrl object which
is then passed to the calib_aeme function.
ctrl <- create_control(method = "calib", VTR = 0, NP = 40, itermax = 400,
reltol = 0.07, cutoff = 0.25, mutate = 0.1,
parallel = TRUE, file_type = "csv",
na_value = 999, ncore = 2)Define variable weights
Weights need to be attributed to each of the selected variables. The weights are used to scale the fitness value. This can be helpful if the variables have different units. For example, if the temperature is in degrees Celsius and the water level is in metres, then the water level will have a much larger impact on the fitness value. Therefore, the weight for the water level should be much smaller than the weight for the temperature.
The weights are specified in a named vector. The names of the vector should be the same as the variable names.
weights <- c("HYD_temp" = 1, "LKE_lvlwtr" = 0.1)Run calibration
Once we have defined the fitness function, control parameters and
variables, we can run the calibration. The calib_aeme
function takes the following arguments:
?calib_aeme| calib_aeme | R Documentation |
Calibrate AEME model parameters using observations
Arguments
aeme |
aeme; object. |
path |
filepath; where input files are located relative to 'config'. |
param |
dataframe; of parameters read in from a csv file. Requires the columns c("model", "file", "name", "value", "min", "max", "log") |
model |
string; for which model to calibrate. Only one model can be passed. Options are c("dy_cd", "glm_aed" and "gotm_wet"). |
model_controls |
dataframe; of configuration loaded from "model_controls.csv". |
vars_sim |
vector; of variables names to be used in the calculation of model fit. Currently only supports using one variable. |
FUN_list |
list of functions; named according to the variables in the
|
ctrl |
list; of controls for sensitivity analysis function created using
the |
weights |
vector; of weights for each variable in vars_sim. Default to c(1). |
param_df |
dataframe; of parameters to be used in the calibration. Requires the columns c("model", "file", "name", "value", "min", "max"). This is used to restart from a previous calibration. |
The calib_aeme function writes the calibration results
to the file specified after each generation. This allows the calibration
to be stopped and restarted at any time. The calib_aeme
function returns the ctrl object with any updated
values.
sim_id <- calib_aeme(aeme = aeme, path = path,
param = aeme_parameters, model = model,
FUN_list = FUN_list, ctrl = ctrl,
vars_sim = vars_sim, weights = weights)
#> Extracting indices for glm_aed modelled variables [2025-07-17 13:01:05]
#> Completed glm_aed! [2025-07-17 13:01:06]
#> Calibrating in parallel for glm_aed using 2 cores...
#> Starting generation 1/10, 40 members. [2025-07-17 13:01:06]
#> Best fit: 1.04 (sd: 437.27)
#> Parameters: [2.01, 0.881, 1.01, 0.122, 0.27, 0.158, 0.42, 0.631, 1.79, 1.93]
#> Writing output for generation 1 to simulation_data.csv with sim ID: 45819_glmaed_C_001 [2025-07-17 13:01:31]
#> Survival rate: 0.75
#> Starting generation 2/10, 40 members. [2025-07-17 13:01:31]
#> Writing output for generation 2 to simulation_data.csv with sim ID: 45819_glmaed_C_001 [2025-07-17 13:01:51]
#> Best fit: 0.88042 (sd: 157.73)
#> Survival rate: 0.98
#> Starting generation 3/10, 40 members. [2025-07-17 13:01:51]
#> Writing output for generation 3 to simulation_data.csv with sim ID: 45819_glmaed_C_001 [2025-07-17 13:02:10]
#> Best fit: 0.81292 (sd: 157.77)
#> Survival rate: 0.98
#> Starting generation 4/10, 40 members. [2025-07-17 13:02:10]
#> Writing output for generation 4 to simulation_data.csv with sim ID: 45819_glmaed_C_001 [2025-07-17 13:02:30]
#> Best fit: 0.81292 (sd: 266.19)
#> Survival rate: 0.92
#> Starting generation 5/10, 40 members. [2025-07-17 13:02:30]
#> Writing output for generation 5 to simulation_data.csv with sim ID: 45819_glmaed_C_001 [2025-07-17 13:02:49]
#> Best fit: 0.75111 (sd: 220.28)
#> Survival rate: 0.95
#> Starting generation 6/10, 40 members. [2025-07-17 13:02:49]
#> Writing output for generation 6 to simulation_data.csv with sim ID: 45819_glmaed_C_001 [2025-07-17 13:03:08]
#> Best fit: 0.67665 (sd: 157.81)
#> Survival rate: 0.98
#> Starting generation 7/10, 40 members. [2025-07-17 13:03:08]
#> Writing output for generation 7 to simulation_data.csv with sim ID: 45819_glmaed_C_001 [2025-07-17 13:03:28]
#> Best fit: 0.67665 (sd: 220.29)
#> Survival rate: 0.95
#> Starting generation 8/10, 40 members. [2025-07-17 13:03:28]
#> Writing output for generation 8 to simulation_data.csv with sim ID: 45819_glmaed_C_001 [2025-07-17 13:03:48]
#> Best fit: 0.67665 (sd: 157.81)
#> Survival rate: 0.98
#> Starting generation 9/10, 40 members. [2025-07-17 13:03:48]
#> Writing output for generation 9 to simulation_data.csv with sim ID: 45819_glmaed_C_001 [2025-07-17 13:04:07]
#> Best fit: 0.67609 (sd: 157.82)
#> Survival rate: 0.98
#> Starting generation 10/10, 40 members. [2025-07-17 13:04:07]
#> Writing output for generation 10 to simulation_data.csv with sim ID: 45819_glmaed_C_001 [2025-07-17 13:04:27]
#> Best fit: 0.65977 (sd: 266.26)
#> Survival rate: 0.92Visualise calibration results
The calibrations results can be read in using the
read_calib function. This function takes the following
arguments:
?read_calib| read_simulation_output | R Documentation |
Read calibration output
Arguments
ctrl |
list; of controls for sensitivity analysis function created using
the |
file_name |
The name of the output file. If |
file_dir |
The directory of the output file. If |
sim_id |
A vector of simulation IDs to read. |
The read_calib function returns a dataframe with the
calibration results. The calibration results include the model,
generation, index (model run), parameter name, parameter value, fitness
value and the median fitness value for each generation.
These results can be visualised using the plot_calib
function. This function takes the following arguments:
-
calib: The calibration results as read in using theread_calibfunction. -
model: The model used for the calibration. -
ctrl: The control parameters used for the calibration.
And returns a list of ggplot objects: a dotty plot, density plot and convergence plot.
calib <- read_calib(ctrl = ctrl, sim_id = sim_id)
plist <- plot_calib(calib = calib, na_value = ctrl$na_value)Dotty plot
This can be used for comparing sensitivity across parameters. The dotty plot shows the fitness value for each parameter value for each generation. The fitness value is on the y-axis and the parameter value is on the x-axis. It is faceted by the parameter name. The parameter values are coloured by the generation. The best fitness value for each generation is shown as a black line with a red dot.
plist$dotty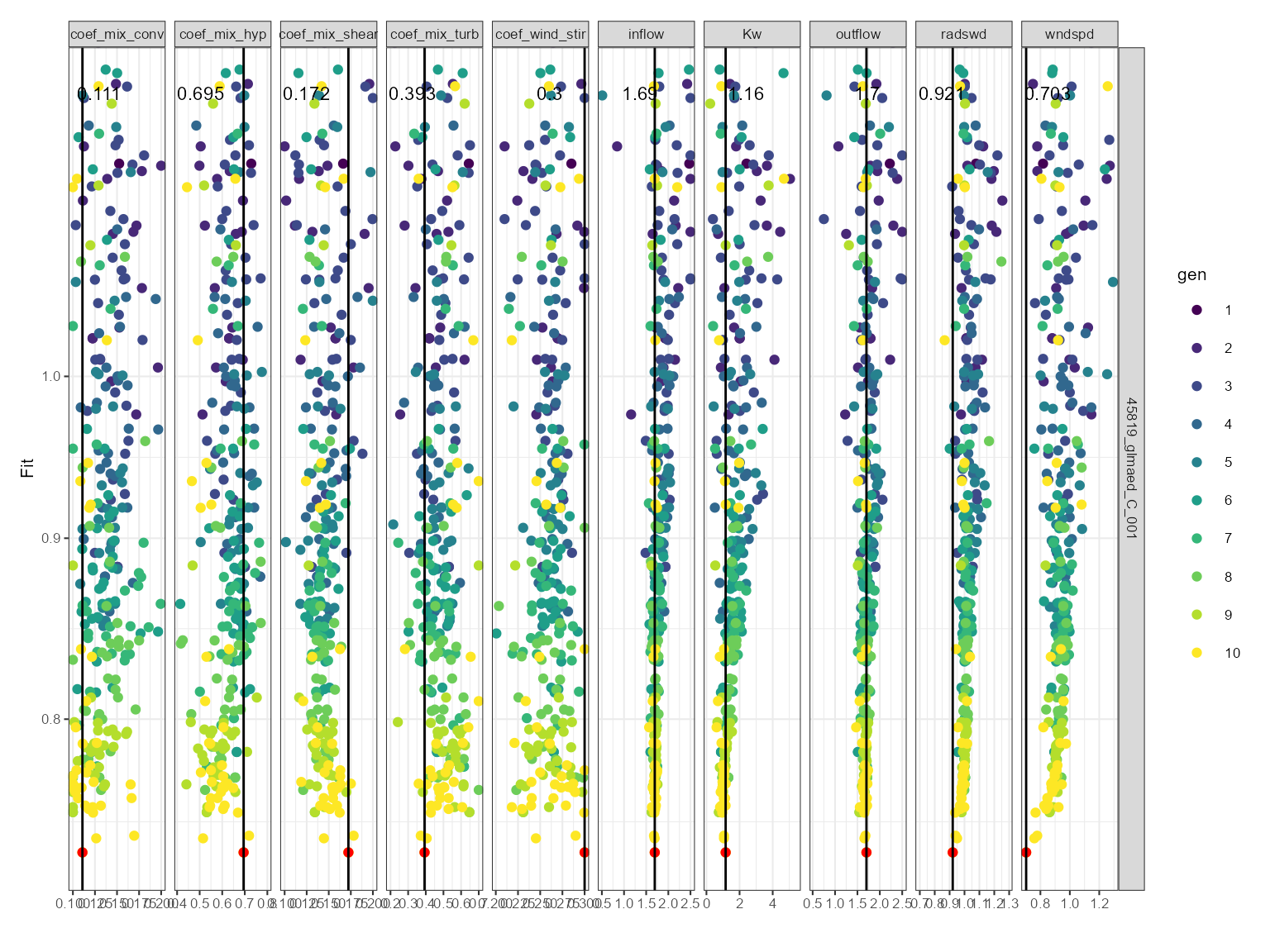
Histogram plot
This is useful for comparing the distribution of parameter values across generations. The histogram plot shows the frequency of the parameter values for each generation. The parameter values are on the x-axis and the density is on the y-axis. It is faceted by the parameter name.
If a parameter is converging on a value, then the histogram will show a peak around that value. If a parameter is not converging on a value, then the histogram will show a flat distribution.
plist$hist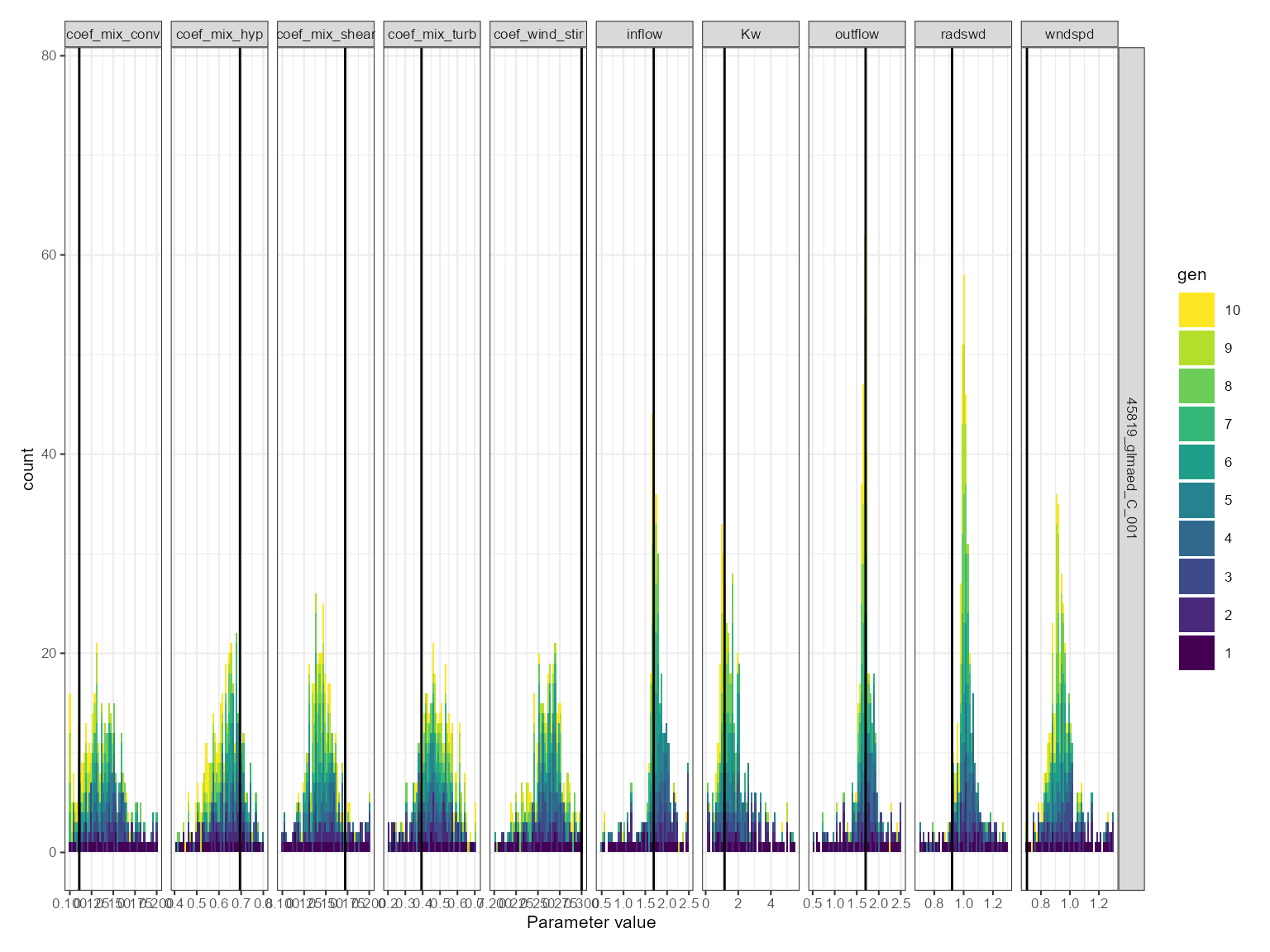
Convergence plot
This is more generally used for assessing model convergence. The convergence plot shows the values use over the iterations. The parameter value is on the y-axis and the iteration is on the x-axis. It is faceted by the parameter name. The parameter values are coloured by the generation. The best fitness value for each generation is shown as a solid horizontal black line.
plist$convergence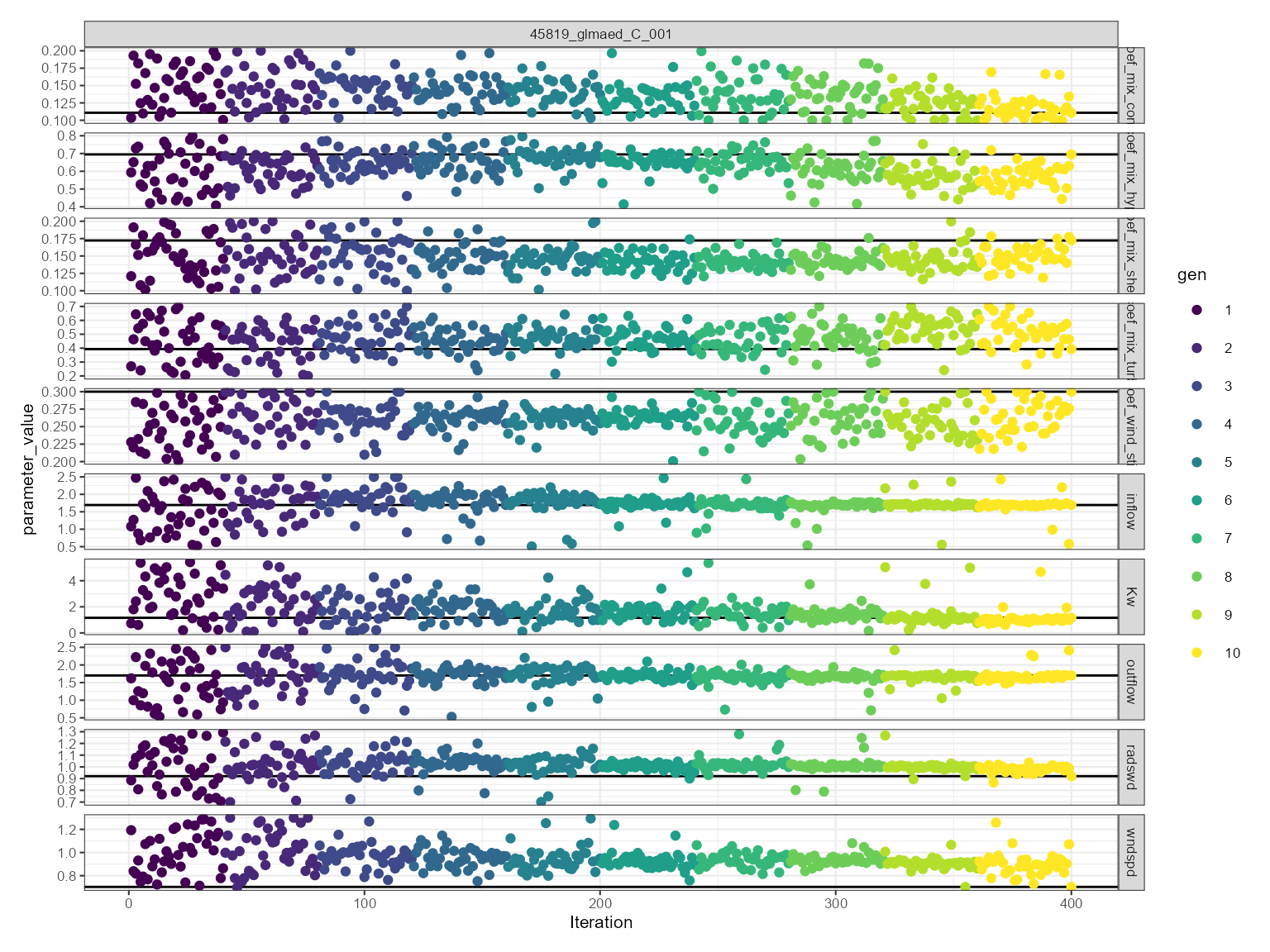
Assess calibrated values
The best parameter values can be extracted using the
get_param function. This function takes the following
arguments:
-
calib: The calibration results as read in using theread_calibfunction. -
na_value: The value to use for missing values in the observed and predicted data. This is used to indicate when the model crashes and then can be easily removed from the calibration results. -
fit_col: The name of the column in the calibration results that contains the fitness value. Defaults tofit. -
best: A logical indicating whether to return the best parameter values or the entire calibration dataset. Defaults toFALSE.
best_params <- get_param(calib, na_value = ctrl$na_value, fit_col = "fit",
best = TRUE)
best_params| sim_id | model | label | fit_type | parameter_value | fit_value | gen | name | group | par |
|---|---|---|---|---|---|---|---|---|---|
| 45819_glmaed_C_001 | glm_aed | Kw | fit | 0.701670 | 0.659773 | 1 | light/Kw | NA | NA |
| 45819_glmaed_C_001 | glm_aed | coef_mix_conv | fit | 0.130507 | 0.659773 | 1 | mixing/coef_mix_conv | NA | NA |
| 45819_glmaed_C_001 | glm_aed | coef_mix_hyp | fit | 0.515081 | 0.659773 | 1 | mixing/coef_mix_hyp | NA | NA |
| 45819_glmaed_C_001 | glm_aed | coef_mix_shear | fit | 0.170018 | 0.659773 | 1 | mixing/coef_mix_shear | NA | NA |
| 45819_glmaed_C_001 | glm_aed | coef_mix_turb | fit | 0.405187 | 0.659773 | 1 | mixing/coef_mix_turb | NA | NA |
| 45819_glmaed_C_001 | glm_aed | coef_wind_stir | fit | 0.281625 | 0.659773 | 1 | mixing/coef_wind_stir | NA | NA |
| 45819_glmaed_C_001 | glm_aed | inflow | fit | 1.436520 | 0.659773 | 1 | inflow | NA | NA |
| 45819_glmaed_C_001 | glm_aed | outflow | fit | 1.356770 | 0.659773 | 1 | outflow | NA | NA |
| 45819_glmaed_C_001 | glm_aed | radswd | fit | 0.891542 | 0.659773 | 1 | MET_radswd | NA | NA |
| 45819_glmaed_C_001 | glm_aed | wndspd | fit | 0.755676 | 0.659773 | 1 | MET_wndspd | NA | NA |
The best parameter values can be used to run the model and compare
the simulated values to the observed values. This can be done using the
run_aeme_param function.
aeme <- run_aeme_param(aeme = aeme, path = path,
param = best_params, model = model,
return_aeme = TRUE)
#> Running models... (Have you tried parallelizing?) [2025-07-17 13:04:31]
#> GLM-AED running... [2025-07-17 13:04:31]
#> GLM-AED run successful! [2025-07-17 13:04:32]
#> Model run complete![2025-07-17 13:04:32]
#> Retrieving and formatting temp for model glm_aed
#> Retrieving and formatting salt for model glm_aedThe simulated values can be compared to the observed values using the
assess_model function. This function takes the following
arguments:
-
aeme: Theaemeobject which has observations and model simulations. -
model: The model to assess. -
var_sim: The variables to use for the assessment.
The assess_model function returns:
?assess_model| assess_model | R Documentation |
Assess model performance
Value
Data frame with model performance statistics for each model and variable. These include:
-
bias - Bias
-
mae - Mean absolute error
-
rmse - Root mean square error
-
nmae - Normalised mean absolute error
-
nse - Nash-Sutcliffe efficiency
-
d2 - Index of agreement model skill score Willmott index
-
r - Pearson correlation coefficient
-
rs - Spearman correlation coefficient
-
r2 - R-squared value from linear model
-
B - Bardsley coefficient
-
n - number of observations
assess_model(aeme = aeme, model = model, var_sim = vars_sim)| Model | var_sim | bias | mae | rmse | nmae | nse | d2 | r | rs | r2 | B | n | obs_na | sim_na |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
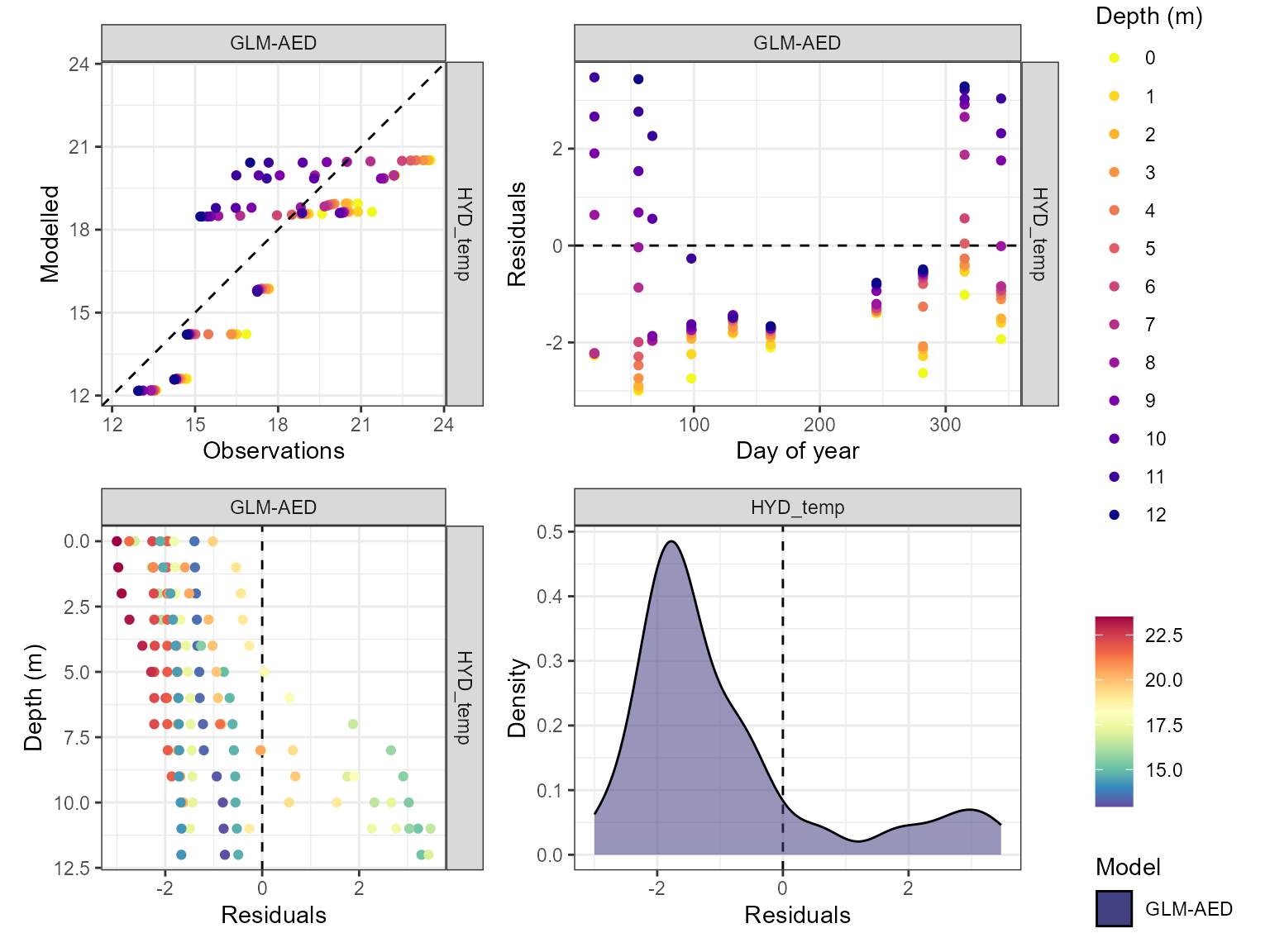
| GLM-AED | HYD_temp | -0.950 | 1.659 | 1.826 | 0.092 | 0.656 | 0.174 | 0.871 | 0.894 | 0.759 | 0.565 | 125 | 0 | 0 |
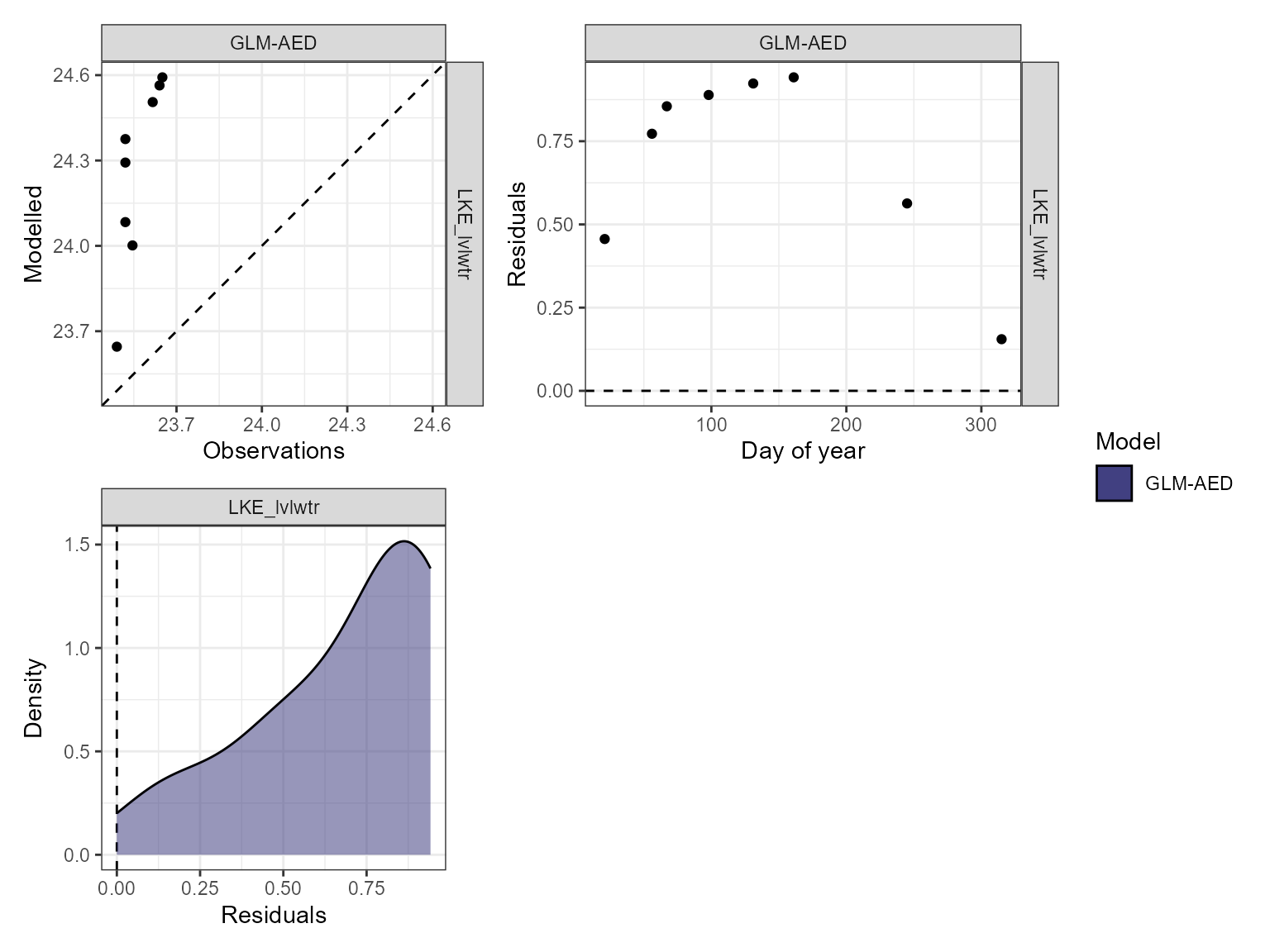
| GLM-AED | LKE_lvlwtr | 0.694 | 0.694 | 0.742 | 0.029 | -159.208 | 0.859 | 0.806 | 0.830 | 0.650 | 0.004 | 8 | 0 | 0 |
Visualise model performance
The model performance can be visualised using the
plot_resid function within the AEME package. This returns a
list of ggplot objects, a plot of residuals for each variable. This is a
multi-panel plot displaying residuals for:
- Observed vs. predicted values
- Residuals vs. predicted values
- Residuals vs. day of year
- Residuals vs. quantiles of the observed values
pl <- plot_resid(aeme = aeme, model = model, var_sim = vars_sim)